Machine Learning für Maker
Überblick Edge Impulse
Die wohl bekannteste Plattform, um mit dem Tiny Machine Learning zu starten, ist Edge Impulse. Da sich diese besonders intuitiv bedienen lässt und trotzdem viele Möglichkeiten bietet, werden wir Edge Impulse in einigen Projekten verwenden. Dieser Beitrag gibt einen grundlegenden Überblick über die Funktionsweise der beliebten Plattform.
Im Beitrag Tools haben wir Edge Impulse bereits vorgestellt. Hier möchten wir Ihnen einen kurzen Einstieg in die Plattform geben.
Öffentliche und private Projekte
Unter diesem Link können Sie sich einen Account bei Edge Impulse erstellen. Wenn Sie bei der standardmäßig kostenlosen Variante bleiben, können Sie aktuell drei private Projekte erstellen. Das bedeutet, dass nur Sie und bis zu zwei von Ihnen eingeladene Personen das Projekt sehen können. Erstellen Sie ein öffentliches Projekt, wird es unter öffentliche Projekte geführt (Public projects) und andere können Ihr Projekt und vor allem auch Ihre hochgeladenen Daten anschauen, herunterladen und selbst verwenden.
Wenn Sie nach Inspiration für ein Projekt suchen, können Sie auch bei den zuvor verlinkten öffentlichen Projekten fündig werden: Ob ein Toaster, der anhand des Geruchs immer das perfekte Toast macht oder ein System, das das Martinshorn erkennt und so gehörlose Verkehrsteilnehmer optisch vorwarnen kann – die Spannweite der öffentlichen Projekte ist sehr groß.
Die wichtigsten Menüpunkte im Überblick
Nachdem Sie sich bei Edge Impulse registriert haben, werden Sie auf die Startseite eines neuen Projektes geleitet. Bei der ersten Anmeldung wird ein Pop-up angezeigt, das Sie zu einem Tutorial leitet. Wenn Sie das Pop-up minimieren, können Sie sich zunächst die Benutzeroberfläche genauer anschauen (siehe Bild 1). Auf der linken Seite befinden sich verschiedene Schaltflächen:
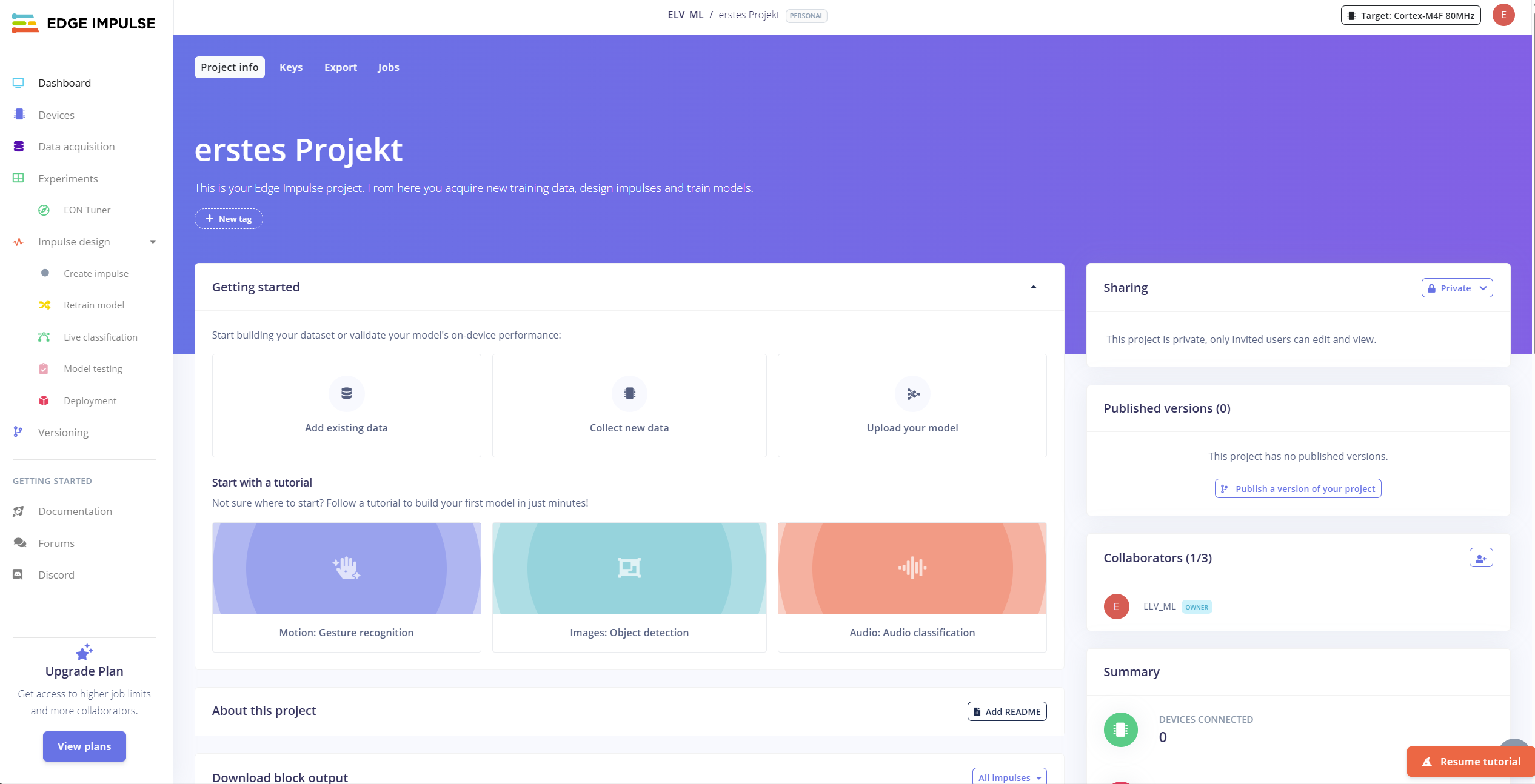
Info: Falls Sie dem Tutorial folgen, werden viele Einstellungen automatisch für Sie getroffen, sodass Sie schnell zu einem Ergebnis kommen. Für die erfolgreiche Umsetzung eigener Projekte lohnt es sich jedoch, sich genauer mit der Plattform auseinanderzusetzen.
- Das Dashboard ist die Startseite, auf der grundlegende Informationen zum Projekt dargestellt werden. Wenn Sie später Daten hinzugefügt und ihre ersten Modelle trainiert haben, können diese hier heruntergeladen werden. Oben rechts wird die aktuelle Zielhardware angezeigt. Diese lässt sich jederzeit anpassen. Sie können eine voll unterstütze Hardware auswählen oder, falls Sie Hardware nutzen, die nicht aufgeführt wird, die Spezifikationen selbst eintragen.
- Unter Devices können Sie Geräte hinzufügen, die Sie zum Aufnehmen der Daten verwenden möchten. Es gibt eine Vielzahl an voll unterstützten Geräten, für die direkt eine Firmware zum Loggen bereitgestellt wird. Ansonsten ist es auch möglich, sich die Sensoren zunutze zu machen, die sich ohnehin in Ihrem Smartphone oder Laptop befinden oder auch über eine Kommandozeilenschnittstelle (Edge Impulse CLI, Data Forwarder) beliebige Sensordaten seriell zu übertragen.
- Wenn Sie bereits Daten aufgenommen haben, können Sie diese auch direkt bei Data acquisition hinzufügen. Der csv-Wizard hilft dabei, Daten im csv-Format richtig zu importieren. Alternativ können auch Cloud-Speicher verwendet werden, um automatisiert neue Daten hinzuzufügen. Wenn Sie ein Gerät hinzugefügt haben, lassen sich hiermit auch neue Daten aufnehmen und labeln. Vorhandene Daten werden hier angezeigt und können bearbeitet werden.
- Sie können mehrere Impulse erstellen und unter Experiments miteinander vergleichen. Auf den Begriff Impulse werden wir im nächsten Absatz genauer eingehen. Als Unterkategorie wird der EON Tuner gelistet. Dies ein Tool, dass es Ihnen ermöglicht, mehrere Einstellungen für die Datenvorverarbeitung und das Modell systematisch auszuprobieren.
- In der Kategorie Impulse design wird der Designflow für das maschinelle Lernen abgebildet. Die Unterkategorien werden je nach verwendetem Modelltypen weiter ergänzt.
- Unter Create Impulse wird die Datenverarbeitungskette festgelegt. Diese nennt sich Impulse und wird im Folgenden noch detaillierter beschrieben.
- Retrain Model ermöglicht es, den gesamten Trainings- und Testvorgang noch einmal durchzuführen, ohne dass jeder Teil einzeln angeklickt werden müsste. Die Voraussetzung dafür ist, dass jeder Teil der Verarbeitungskette zunächst einmal initial ausgeführt wurde. Das ist vor allem dann praktisch, wenn neue Daten hinzugekommen sind oder falls Sie einige Einstellungen bei den Blöcken verändert haben.
- Es ist möglich, das erstellte Modell beim Menüpunkt Live classification direkt im Browser zu testen. Dadurch entfällt zunächst der aufwendige Schritt, das Modell auf die Zielhardware zu übertragen. Wenn ein Gerät verbunden ist, können damit live neue Daten aufgenommen werden. Alternativ können auch bereits aufgenommene Daten noch einmal betrachtet und die Entscheidung genauer analysiert werden.
- Bei der Aufnahme der Daten kann man Daten zum Trainings- oder Testdatensatz hinzufügen. Die Daten im Testdatensatz werden fürs Training außen vorgelassen und erst beim Menüpunkt Model testing zum ersten Mal verwendet, um die Leistung des Modells auf unbekannten Daten zu testen.
- Der letzte Punkt, Deployment, dient dazu, das trainierte und im Idealfall ausführlich getestete Modell mitsamt der Vorverarbeitungskette in eine Bibliothek zu exportieren. Hier können noch Einstellungen getroffen werden, die die Inferenzzeit und den benötigten Speicher beeinflussen.
- Unter Versioning können wie mit Git Zwischenstände des Projekts gespeichert und zu einem späteren Zeitpunkt wiederhergestellt werden.
Impulse für die Signalverarbeitung
Der Impulse ist das Herzstück des Machine Learning Designflows von Edge Impulse, da dieser die gesamte Datenverarbeitung von den Rohdaten bis zum Ergebnis abbildet. Dieser Impulse besteht, wie in Bild 2 zu sehen, aus den drei Blöcken Eingangs-, Signalverarbeitungs- und Modellblock.

- Der Eingangsblock nimmt die Rohdaten auf und zerteilt diese in kleinere Fenster, falls Zeitreihen wie Audio- oder Bewegungsdaten vorliegen. Dort können dazu passende Einstellungen vorgenommen werden. Diese sind zum Beispiel die Fenstergröße, der Fensterversatz und die Frequenz. Bei Bildern wird die Bildgröße angepasst. Heraus kommen Datenblöcke mit einer einheitlichen Größe, die im zweiten Block Signalverarbeitung weiterverwendet werden.
- Der Block Signalverarbeitung dient dazu, die Daten von Zeitreihen in aussagekräftigere Eigenschaften (sogenannte Features) umzusetzen: Würden wir die Rohdaten von zum Beispiel einem Beschleunigungsmessser in ein Modell geben, um bestimmte Bewegungen zu klassifizieren, wird man mit kleinen neuronalen Netzen (ohne Deep Learning) nicht weit kommen. Denn viel wichtiger als die Absolutwerte sind hierfür beschreibende Eigenschaften des Signals. Für Standardanwendungen wie Vibrationsanalyse, Audio- und Bildverarbeitung sind bereits Vorverarbeitungsblöcke implementiert, die zum Beispiel Spektralanalysen oder statistische Analysen durchführen. Es ist auch möglich, hier eigene Vorverarbeitungsblöcke einzubinden, wenn die zur Verfügung stehenden nicht ausreichen.
Es können mehrere Vorverarbeitungsblöcke eingebunden werden. Für jeden Block erscheint links ein neuer Menüpunkt, unter dem Einstellungen zum Block vorgenommen werden können. - Im dritten Block, dem Modellblock, wird der Aufgabentyp festgelegt. Das bedeutet, dass die Aufgabe des Modells festgelegt werden soll. Edge Impulse unterscheidet in Klassifikation, Regression, Anomalieerkennung, Objekterkennung und Transfer Learning. Die genaue Architektur wird im dazugehörigen Unterpunkt (z. B. Classifier, Anomaly detection) festgelegt. Auch bei diesem Block ermöglicht Edge Impulse, bei Bedarf eigene Blöcke zu erstellen und hochzuladen (Bring Your Own Model). Bei einigen Modelltypen (vor allem klassisches Machine Learning mit scikit-learn) ist es mit der Standardlizenz jedoch nicht möglich, später auch Modellbibliotheken zu exportieren.
Am Ende des Modellblocks steht eine Ausgabe, die zum Beispiel eine Klasse oder einen vorhergesagten Wert beinhalten kann. In Edge Impulse ist es auch möglich, mehrere Modelle einzusetzen.
Wissen: Beim maschinellem Lernen wird in überwachtes und unüberwachtes Lernen unterschieden. Beim überwachten Lernen, auch englisch supervised learning, ist zu jedem Trainingsbeispiel das eingetretene Ergebnis bekannt. Diese Daten besitzen daher ein Label. Die Ausgabe eines Modells kann im Training also mit der wahren Ausgabe verglichen werden. Anhand der Ergebnisse können auch Bewertungsmetriken berechnet werden, die die Güte des Modells in Zahlen fassen können. Typische Anwendungsfälle sind die Klassifikation, bei der die Daten in verschiedene Klassen eingeteilt werden oder die Regression, bei der kontinuierliche Werte ausgegeben werden.
Beim unüberwachten Lernen, auch englisch unsupervised learning, ist das Ergebnis entsprechend unbekannt. Hierbei geht es zum Beispiel darum, in Daten nach Gruppen oder Anomalien zu suchen und diese weiter zu untersuchen.
Zusammenhang mit dem CRISP-DM Modell
In diesem Beitrag haben wir einen Standardprozess für Machine Learning Projekte vorgestellt. Auch, wenn der Edge Impulse Workflow nicht exakt den CRISP-DM Prozess abdeckt, finden sich viele Phasen wieder. Das Datenverständnis findet sich vor allem unter Data acquisition wieder, auch wenn für bestimmte Funktionen bereits ein fertiger Impulse gefordert wird. Der Impulse deckt vor allem die Phasen Datenvorverarbeitung und Modellbildung ab. Mithilfe der Funktionen des (Live) Testens kann das Modell evaluiert werden und der Unterpunkt Deployment ist der Ausgangspunkt für die Einbettung des Impulses in ein Projekt.
In diesem Beitrag wurde ein grober Überblick über die Funktionsweise der Plattform Edge Impulse gegeben. Edge Impulse hat neben den erwähnten Grundfunktionen noch viele tiefergehende Einstellungen. Ein besonders großer Vorteil ist, dass sich fehlende Funktionen, vor allem in der Signalverarbeitung, häufig selbst implementieren lassen. In den nächsten Beiträgen werden wir anhand von Beispielprojekten näher auf nützliche Funktionen und technische Hintergründe eingehen.