Machine Learning für Maker
Ablauf von TinyML-Projekten: der CRISP-DM-Prozess
AutoML-Anbieter wie Edge Impulse oder Neuton AI erleichtern das Arbeiten mit Tiny Machine Learning, indem sie Pipelines zur Verfügung stellen, die durch die Entwicklung leiten. Auch wenn AutoML-Tools wie Edge Impulse eigene Workflows haben, lassen sich viele ihrer Schritte grob in den CRISP-DM-Prozess einordnen. Dieser kann als Orientierung für die Einarbeitung in neue Tools dienen.
Was ist CRISP-DM?
Im Beitrag TinyML-Tools für Maker sind wir bereits auf die unterschiedlichen Tools eingegangen, die für TinyML-Projekte verwendet werden können. Besonders interessant dürften für viele die AutoML-Tools sein, die fast den gesamten Entwicklungsprozess vom Sammeln der Daten bis hin zur Erstellung ganzer Firmwares unterstützen. Weil häufig nur wenig oder gar nicht programmiert werden muss, ist der Einstieg leicht und erste Ergebnisse lassen sich schnell erkennen.
Dabei funktionieren die Anwendungen nach einem ähnlichen Prinzip: Nachdem die Zielhardware festgelegt wurde, werden die Daten aufgenommen oder hochgeladen, sie werden analysiert und es findet in irgendeiner Form eine Aufbereitung der Messwerte beziehungsweise des Signals statt. Daran angeschlossen werden unterschiedliche Modelle gebildet und ausgewertet. Bei AutoML-Tools wird dies zu großen Teilen automatisiert. Für TinyML ist der letzte Schritt der Export in eine optimierte Bibliothek oder sogar als fertige Firmware.
Genau dieser Ablauf wird im CRISP-DM-Prozess genauer beschrieben. CRISP-DM steht für Cross Industry Standard Process for Data Mining (branchenübergreifender Standardprozess für Data-Mining oder Data-Science-Projekte) und ist ein iterativer Prozess, der aus sechs Phasen besteht. Diese sind:
- Business Understanding (Geschäftsverständnis)
- Data Understanding (Datenverständnis)
- Data Preparation (Datenvorbereitung)
- Modeling (Modellbildung)
- Evaluation
- Deployment (Bereitstellung)
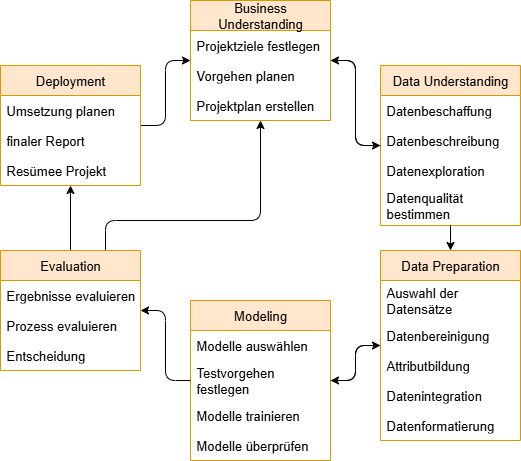
Wie in Bild 1 schon erkennbar ist, handelt es sich hierbei nicht um einen Prozess, dessen Phasen strikt nacheinander abgeschritten werden. Vielmehr ist es ein iterativer Prozess, bei dem Rückschritte gemacht werden, um das Ergebnis anzupassen, nachzubessern oder robuster zu machen. Die einzelnen Phasen und Teilphasen werden in den folgenden Abschnitten genauer in Bezug auf die Anwendung im Bereich TinyML erläutert. Die Phasen zwei bis fünf lassen sich fast vollständig mit den meisten AutoML-Tools durchführen.
Das Problem verstehen: Business Understanding
In der Industrie werden in der ersten Phase Absprachen zwischen der auftraggebenden und der ausführenden Seite getroffen. Dabei wird das Vorgehen geplant und die Erfolgskriterien werden festgelegt. Auch wenn Sie bei privaten Projekten beide Rollen einnehmen werden, kann es sinnvoll sein, sich klarzumachen, welche Ziele Sie erreichen möchten, um so spätere Ergebnisse damit vergleichen zu können. Diese Phase wird nur teilweise von AutoML-Tools abgebildet. Bei den meisten Anwendungen können ein Controller sowie Sensoren angegeben werden, die verwendet werden sollen. Im weiteren Verlauf werden diese Angaben zum Beispiel dafür genutzt, dass nur nach Modellen gesucht wird, die auch auf der Zielhardware umsetzbar sind. Außerdem muss zu Beginn häufig schon angegeben werden, ob das Ziel eine Klassifikation, Regression oder Anomalieerkennung ist. Sie sollten sich zu Beginn zum Beispiel folgende Fragen stellen:
- Was möchte ich erreichen? Möchte ich nur ausprobieren, ob meine Idee funktionieren könnte, oder möchte ich mein Ergebnis am Ende auch z. B. im Smart Home einsetzen?
- Welche Hardware möchte ich nutzen? Gibt es vielleicht noch andere Sensoren, die ich testen könnte?
- Welches System liegt vor oder welche Annahmen kann ich darüber treffen?
Verständnis zeigen: Data Understanding
Entscheidend für den Erfolg eines Projekts sind die Daten. Sie müssen auf sinnvolle Weise aufgenommen werden, denn: Garbage In, Garbage Out. Das bedeutet, wenn schlechte Daten verwendet werden, wird auch das spätere Modell nicht gut sein. Daher sollten Sie sich einen Überblick über die aufgenommenen Daten verschaffen. AutoML-Tools unterstützen Sie dabei: Sie helfen bei der Erstellung von Datenloggern oder beim Hochladen bereits aufgenommener Daten und bringen diese sofort in das für den Workflow richtige Format. Die Daten werden visualisiert und statistisch ausgewertet. Dabei sollten Sie ein Gefühl für die Beschaffenheit der Daten erhalten und auf Auffälligkeiten wie Rauschen oder Muster achten.
- Welche Daten liegen bereits vor? Sind sie vollständig oder fehlen wichtige Messwerte?
- Wie sehen typische Messverläufe aus? Gibt es Ausreißer oder Rauschen?
- Welche Zusammenhänge lassen sich erkennen? Gibt es Muster oder Trends?
- Wie häufig und in welcher Form werden die Daten erfasst (z. B. kontinuierlich, in Intervallen)?
- Messe ich mit einer sinnvollen Abtastrate?
Vorbereitung ist alles: Data Preparation
In diesem Schritt werden die Daten für die anschließende Modellbildung vorbereitet. Das bedeutet, dass hier Signalverarbeitung, Skalierung und das sogenannte Feature-Engineering stattfinden. Das Ziel ist, möglichst aussagekräftige Eigenschaften zu finden, die relevant für die Entscheidung sind. Das Besondere bei TinyML ist, dass bei dieser Vorbereitung der Daten auch die Leistungsfähigkeit des später eingesetzten Controllers beachtet werden muss. So können die auftretenden Frequenzen sehr viel über das System verraten, gleichzeitig ist eine FFT (Fast Fourier Transformation) ein aufwendiger Schritt, der die Leistungsfähigkeit von Mikrocontrollern übersteigen kann. AutoML-Tools bieten hier meist vorgefertigte Blöcke an, die beim Feature-Engineering unterstützen und eine Einschätzung geben können, ob der Mikrocontroller diese Signalverarbeitung leisten kann. Auch wenn es verlockend wirkt, schnell zum Modeling überzugehen, lohnt es sich, genügend Zeit in die Untersuchung und Vorbereitung der Daten zu investieren. Dadurch können Probleme mit den Daten frühzeitig erkannt und behoben werden.
- Müssen die Daten gefiltert, normalisiert oder skaliert werden, um Rauschen oder Ausreißer zu eliminieren?
- Welche Features sind relevant für mein Ziel? Kann ich unwichtige Merkmale entfernen?
- Schafft der Mikrocontroller die Datenvorverarbeitung in der zur Verfügung stehenden Zeit mit dem verfügbaren Speicher?
- Benötige ich maschinelles Lernen oder kann ich mit klassischer Signalverarbeitung genauso gute Ergebnisse erzielen?
Aus Daten wird Wissen: Modeling
Jetzt beginnt die eigentliche Modellbildung. AutoML-Tools übernehmen diesen Schritt meist vollständig: Sie testen verschiedene Modellarchitekturen (z. B. neuronale Netze und Entscheidungsbäume) und bewerten deren Leistung anhand definierter Metriken wie der Genauigkeit, dem F1-Score oder dem Speicherverbrauch. Besonders bei TinyML ist die Auswahl eines Modells, das auf der Zielhardware lauffähig ist, entscheidend. Teilweise können aber auch konkrete Modellarchitekturen vorgeben werden.
Info: Anhand von Bewertungs- und Validierungsmetriken können Aussagen zur Modellqualität getroffen und potenzielle Probleme identifiziert werden. Da es sich um wichtige Kennzahlen handelt, werden wir bei Beispielprojekten gesondert darauf eingehen.
- Kann ich die Modellarchitektur beeinflussen oder wird sie vollständig automatisch gewählt?
- Gibt es eine Möglichkeit, die Modellkomplexität zu reduzieren?
- Welche Metriken verwendet das Tool zur Bewertung der Modelle? Kann ich eigene Kriterien festlegen?
- Wird das Modell auf Basis meiner Daten neu trainiert oder nutzt das Tool vortrainierte Modelle?
- Kann ich mehrere Modelle vergleichen und das passendste auswählen?
Die Qualität prüfen: Evaluation
Die Bewertung des Modells erfolgt anhand von Testdaten oder Validierungsmetriken. AutoML-Tools zeigen oft direkt an, wie gut das Modell performt, zum Beispiel indem es Konfusionsmatrizen, ROC-Kurven oder einfache Erfolgsquoten aufzeigt. In dieser Phase wird entschieden, ob das Modell ausreichend gut ist oder ob weitere Anpassungen nötig sind. Auch hier können Sie iterativ zurückgehen, z. B. zur Datenvorbereitung oder zur Auswahl anderer Modelltypen. Die Evaluation ist besonders wichtig, um sicherzustellen, dass das Modell nicht nur auf Trainingsdaten gut funktioniert, sondern auch auf neuen, unbekannten Daten. Hier wird bei den AutoML-Tools auch teilweise die Möglichkeit des Live-Testens gegeben. Sie können Ihren Datenlogger häufig nutzen, um zum Beispiel per USB neue Daten zu streamen, die gemäß der festgelegten Signalverarbeitung und dem Modell auf Ihrem PC so verarbeitet werden, als wäre die Datenverarbeitungskette bereits auf Ihrer Zielhardware umgesetzt. Das gibt Ihnen die Möglichkeit, die Funktionalität sofort zu testen und gegebenenfalls anzupassen, ohne dass Sie bereits Zeit in die Umsetzung auf dem Mikrocontroller investieren müssen. Erreicht das beste Modell nicht die zuvor gesetzten Anforderungen, sollten Sie einen oder mehrere Schritte zurückgehen. Möglicherweise ist es auch nötig, neue Daten aufzunehmen.
- Wie groß ist das Modell und passt es in den verfügbaren Speicher meines Mikrocontrollers?
- Wie lange dauert die Inferenzzeit auf der Zielhardware? Ist sie für mein Projekt ausreichend schnell?
- Wie gut funktioniert das Modell auf neuen, unbekannten Daten?
- Welche Metriken sind für mein Projekt relevant (z. B. Genauigkeit, F1-Score, Fehlerrate)?
- Gibt es bestimmte Szenarien, in denen das Modell versagt? Kann ich diese nachtrainieren?
- Ist das Modell robust genug für den späteren Einsatz?
Export für die Anwendung: Deployment
Wenn die Ergebnisse aus der Evaluation den Ansprüchen gerecht werden, werden die Signalverarbeitung und das Modell auf den Mikrocontroller übertragen. Die meisten AutoML-Tools bieten hierfür den Export von Bibliotheken (C/C++ oder vorkompilierte) an. Teilweise kann aber auch schon fertige Firmware exportiert werden. Um Speicherplatz und Verarbeitungszeit zu sparen, kann an dieser Stelle häufig auch eine Quantisierung gewählt werden. Dabei werden die Modellparameter von Float- in Integerwerte übertragen. Dabei kann es zu einer Verschlechterung der Genauigkeit kommen. Wird keine fertige Firmware erstellt, müssen die exportierten Bibliotheken selbst in einer Firmware eingebettet werden.
- In welchem Format kann ich das Modell exportieren (z. B. C-Array, Bibliothek, Firmware)?
- Wird das Modell direkt auf meine Zielhardware zugeschnitten?
- Muss ich das Modell noch selbst in meine Anwendung integrieren oder übernimmt das Tool das vollständig?
- Welche Optimierungen kann ich beim Export aktivieren?
- Wie viel Speicherplatz benötigt das Modell nach dem Export? Passt es mit den anderen Firmwareanteilen auf meinen Mikrocontroller?
Besonderheiten bei TinyML
Die AutoML-Tools Edge Impulse, Neuton AI und Nano Edge AI nutzen, wie eingangs erwähnt, eigene Workflows, die CRISP-DM nicht direkt abbilden. In den vorherigen Abschnitten wurde immer wieder auf die Besonderheiten bei TinyML-Projekten eingegangen. Ein zentraler Unterschied zwischen den TinyML-Workflows und dem CRISP-DM-Modell ist der Fokus der TinyML-Workflows auf die eingesetzte Hardware. In fast jeder Phase wird Rückbezug darauf genommen, da die starke Beschränkung von Rechenleistung und Speicher besonders effiziente Signalverarbeitung und Modelle fordert. Durch die fast vollständige Automatisierung der Datenverarbeitung und Modellbildung ist es möglich und vorgesehen, viele Iterationen der vorgestellten Phasen durchzuführen, bis ein finales Modell exportiert werden kann. Bei CRISP-DM hingegen liegt der Fokus eher weniger auf der eingesetzten Hardware als auf der systematischen Analyse und dem Verständnis der Daten im Kontext eines Geschäftsproblems. Die einzelnen Phasen sind bewusst offen gehalten, um sie flexibel auf verschiedene Branchen und Problemstellungen anwenden zu können. Während TinyML-Workflows stark auf technische Machbarkeit und Ressourcennutzung ausgerichtet sind, zielt CRISP-DM auf eine strukturierte, dokumentierte Vorgehensweise, bei der die Nachvollziehbarkeit und das methodische Vorgehen im Vordergrund stehen.
Trotz der Unterschiede kann das CRISP-DM-Modell Ihren Projekten eine Struktur geben und verschiedene AutoML-Tools miteinander vergleichbar machen. Ein inhaltlicher Vergleich der verschiedenen Tools ist in diesem Beitrag zu finden.